
Périodicité aléatoire pour cette chronique (la n°5 arrive deux mois après la précédente, fin février dernier) avec une sélection resserrée d’articles partagées, à titre personnel, sur Linkedin. La recherche d’informations sur le web ne cesse d’évoluer, au croisement des résultats Google (les SERP) et des citations ou mentions par une IA générative (ChatGPT, Perplexity, Gemini pour les trois plus connues) en réponse à une requête effectuée sur une plateforme LLM (éponyme).
Comment optimiser de façon efficace pour une visibilité globale ? Un site web 100% conforme aux attendus Google (technique, contenu, maillage interne et backlinks) et aux attentes des LLM quant à la structure des contenus – entre Query fan-out et extractibilité ou chunking – semble un premier pré-requis afin de le placer au cœur d’un écosystème de diffusion multicanal.
Pour le reste, et c’est un paradoxe comme le montrent les trois articles partagés et chroniqués ci-dessous, plus l’on parle d’optimisation de la visibilité globale sur le Web, plus c’est flou !
Au sommaire de cette chronique n°5
- Contenu web et IA générative : l’Ouroboros numérique se dévore à chaque requête
- Etre cité ou mentionné par une IAG, ce n’est pas la même chose
- Contenu web : du TOFU pour les IAG, du BOFU pour Google
Contenu web et IA générative : le serpent qui se mord la queue
Pour revenir sur l’effondrement (model collapse) présumé des grands modèles de langage dits LLM, et des boucles d’IAG sources de slop content, Pedro Dias refait le match, en s’appuyant sur de précédentes publications (celle de Lily Ray sur Perplexity, intitulée The AI slop loop et celle de Thomas Germain de la BBC sous le titre I hacked ChatGPT and Google’s AI – and it only took 20 minutes), le tout étant actualisé à l’aune du récent papier How Accurate Are Google’s A.I. Overviews?, publié par le The New York Times, le 7/04/26, et qui est centré – comme son titre l’indique – sur les AI Overviews, non encore disponibles en France.
Le risque croissant d’un appauvrissement du langage
En résumé, dans sa conception initiale Pedro Dias définissait ainsi l’Ouroboros numérique : « On entraîne un modèle sur du texte web, le web se remplit de productions d’IA, le modèle suivant s’entraîne sur un corpus de plus en plus composé de ses propres résultats, et finalement la distribution s’aplatit complètement. L’innovation provient des exceptions, et les systèmes probabilistes qui convergent vers la moyenne atténuent les exceptions par construction. »
Car, rappelons-le, les LLM fournissent des réponses statistiques à partir des correspondances entre la question et les patterns dans leurs bases de connaissances. D’où la convergence vers la moyenne et le risque de « flatten langage » (langage aplati) à terme.
En l’état des connaissances (il s’agit de constats documentés et non de science), pour qui s’intéresse à la recherche d’informations sur le web, à la rédaction de contenu de qualité et à l’optimisation de la visibilité globale, faut-il changer de métier au regard de la vitesse fulgurante à laquelle le train file… et semble en passe de dérailler ?
Quand l’Ouroboros numérique se dévore à chaque requête
Que nous explique Pedro Dias en s’appuyant sur les constats de Lily Ray, Thomas Germain et du NY Times : « Le cadre de réflexion [ndlr : le cadre initial de l’Ouroboros numérique] supposait des cycles d’entraînement et du temps. Il supposait que la contamination se propageait à la vitesse de la diffusion du modèle. En fait, tout cela ne semble pas relever de l’entraînement. Les modèles impliqués n’ont pas été à nouveau entraînés entre l’apparition de cette hallucination sur un blog et sa présentation comme fait avéré, preuves à l’appui. La contamination s’est propagée à une vitesse fulgurante. L’Ouroboros ne met pas des générations à se dévorer lui-même. Il se dévore à chaque requête, chaque fois que quelqu’un interroge l’un de ces systèmes. »
Il convient de lire cet article jusqu’à sa conclusion : « L’effondrement du système de récupération ne peut attendre la prochaine phase d’entraînement. Il nécessite une URL indexable et un système de récupération qui lui fasse confiance. Les systèmes sont disposés à le faire. Et plus de la moitié du temps, même lorsqu’ils donnent la bonne réponse, ils sont incapables de citer une source qui confirme ce qu’ils viennent de vous dire. »
- The Ouroboros Learned to Cited Itself (Pedro Diaz, 21/04/26)
- What is AI slop? A technologist explains this new and largely unwelcome form of online content (The Conversation France, 02/09/25)
Citation ou mention par une IAG, la nuance est importante
L’intérêt de la période – quant au web investi par l’intelligence artificielle générative (IAG) – est sa dimension exploratoire. Depuis les débuts de PageRank jusqu’à la stabilisation de l’index de Google, nous avions des repères précis.
Certes, les mises à jour de l’algorithme sont toujours fréquentes avec des résultats parfois surprenants. L’ensemble reste une boîte noire : l’expérience et les strates de données accumulées au fil du temps permettent néanmoins de s’adapter. L’optimisation se joue sur quatre piliers : technique, contenu EEAT, maillage interne et linking. Sans oublier la double dimension architecture de l’information (qui induit l’arborescence) et UX (expérience utilisateur) pour la navigabilité.
Recherche web et réponses générées par IA depuis les LLM : on navigue à vue
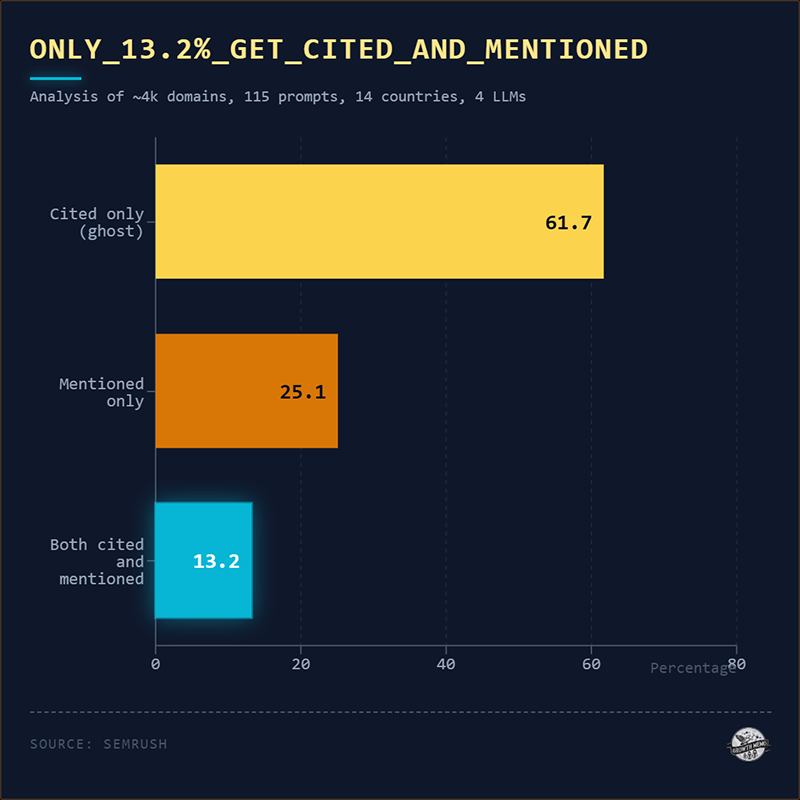
Avec la recherche d’informations depuis les nouvelles plateformes LLM, on garde ces fondamentaux, mais on rajoute une sur-couche ! Comme le montre cette étude, publiée par Search Engine Journal et commentée par Kevin Indig, adossée à l’analyse de 3.981 domaines, répartis sur 115 requêtes, 14 pays et 4 moteurs de recherche d’IA (ChatGPT, Google AI Overviews, Gemini et AI Mode), le tout avec l’outil Semrush AI Toolkit, et bien… nous naviguons à vue.
Quels enseignements tirer même si tout cela reste empirique, mais permet de progresser dans la compréhension des mécanismes en jeu ?
« Lorsqu’une IAG répond à une question en utilisant votre contenu, elle vous cite généralement avec un lien vers la source. Cependant, dans 62 % des cas, elle ne mentionner votre nom [ndla : votre marque, entreprise, organisation]. Le lien est présent, mais la mention de votre marque est absente » explique Kevin Indig.
ChatGPT, Gemini, Google AI et AI Mode : quatre fonctionnements différents
De surcroît, les 4 LLM testés ne semblent pas avoir le même mode de fonctionnement, l’affichage des résultats différant de l’un à l’autre. Comme l’écrit l’auteur : « Optimiser l’un n’améliore pas l’autre. Il n’existe pas de ” métrique de visibilité IA ” unique. Au moins quatre systèmes comportementaux différents fonctionnent en parallèle. »
Autre point important : être cité et être mentionné… ne sont pas des affirmations synonymes, au sens de la visibilité IA. Au moment de l’analyse d’un domaine, dans le cadre d’un audit, il convient donc de distinguer une occurrence citée (lien vers la source présent) ou mentionnée (nom de la marque dans le texte de la réponse générée).
Les données de l’étude indiquent que seulement « 13,2 % des occurrences se traduisent à la fois par une citation et une mention ». Kevin Indig avoue les limites actuelles de compréhension : « Etre cité signifie qu’une IA utilise votre contenu. Etre mentionné signifie qu’elle vous nomme. Nous ne connaissons pas encore toutes les implications des mentions et des citations, mais nous pouvons affirmer avec certitude qu’il existe un système qui détermine si vous êtes cité ou mentionné. »
- The Ghost Citation Problem (Kevin Indig, 21/04/26)
Moins de TOFU, plus de BOFU !
Moins de trafic mais mieux de trafic. A mesure que le contenu de découverte (informationnel) perd en performances (moins de clics) depuis Google au bénéfice des requêtes depuis les plateformes LLM, le contenu de conversion (transactionnel) de bas de funnel semble garder son potentiel. Autant donc consacrer nos efforts à créer des pages à valeur 100% ajoutée, plus basses dans l’entonnoir, là ou le visiteur et prospect est au plus proche de la phase d’achat.
L’avantage d’une telle approche, c’est qu’elle est aussi en phase avec les principes de sobriété éditoriale, prônés par Ferréole Lespinasse. Elle privilégie la qualité, l’authenticité, l’expertise… nous tendons vers le EEAT… et procure à l’organisation y souscrivant un avantage concurrentiel potentiel vs les partisans du contenu automatisé full AIG (conviction personnelle, mais les experts crédibles (pas les auto-proclamés) de la communauté SEO sont assez d’accord sur le sujet.

On en revient à l’approche user centric : répondre à la question que se pose réellement un acheteur, et non à celle qui génère le plus de recherches. Dans cette conception le rôle du contenu TOFU (Top Of The Funnel) serait désormais plutôt de développer une autorité thématique qui contribue au référencement des pages BOFU (Bottom Of The Funnel), celles dévolues à la découverte via les requêtes de nature informationnelle : celles-ci semblent être aujourd’hui les premières concernées par le déplacement de l’usage de recherche d’informations sur le Web, de Google vers les LLM.
Revoir votre mesure de la performance du contenu, élargir le champ des indicateurs analysés
Si les entreprises doivent s’adapter, les agences conseil en optimisation de la visibilité globale sur le web, tout autant, car la part sémantique de l’analyse devient centrale. Les outils SaaS du marché délivrent de la donnée (parfois en erreur au regard du récent bug dévoilé quant aux impressions erronées depuis la Search Console ou les résultats fantaisistes renvoyés par Google à Semrush et consorts en réponse au scrap des SERP).
Les fondamentaux du SEO fournissent les bases éprouvées sur lesquelles il convient de construire ; ensuite… et c’est le côté enthousiasmant de la période en cours, il faut innover et se réinventer.
- Why bottom-of-funnel content is winning in AI search (Kristina Frunze, 17/04/26)
Pierre Minier
- Chronique IA générative n°1 (08/11/25)
- Chronique IA générative n°2 (25/12/25)
- Chronique IA générative n°3 (03/01/26)
- Chronique IA générative n°4 (28/02/26)



