
Une nouvelle édition de cette chronique plus ou moins mensuelle de l’IA générative, des LLM et de l’évolution de la recherche sur le web. La nouvelle équation se confirme : la visibilité globale d’une organisation associe désormais le meilleur classement dans les résultats de recherche classiques (Google et Bing) et la capacité à être cité dans les réponses génératives aux questions posées par les utilisateurs depuis les plateformes LLM (ChatGPT, Perplexity, Gemini…).
Nous le verrons dans une prochaine chronique, ces mentions et citations par les IA/LLM sont très volatiles comme le montre une étude récente Spark Toro. Dans le même temps, la qualité moyenne du contenu tend à se dégrader quand – justement – cette qualité du contenu est le critère n°1 de différenciation. Nous sommes de plain-pied dans l’ère des paradoxes de la technologie.
Les articles qui suivent sont issus d’une veille quotidienne et sourcée sur LinkedIn. Synthèse ici des publications de la première quinzaine de janvier 2026.
Au sommaire de cette chronique n°4
- Le SEO devient une discipline complexe d’intégration (Duane Forrester, 11/01/26)
- Google minimise l’importance de l’optimisation du contenu pour la recherche générative (Search Engine Journal, 13/01/26)
- Avoir raison ne suffit plus pour assurer aujourd’hui la visibilité de son contenu depuis la recherche IA (Duane Forrester, 04/01/26)
- Etude ADEME (06/01/26) sur les datacenters et l’impact sur la consommation électrique en France
- Dégradation du contenu et grangrène du slop AI sur le web (Search Engine Journal, 05/01/26)
- Evolution du SEO à l’ère de l’IA générative : sémantique, entité, topic clusters (Search Engine Land, 31/12/25)
SEO Is No Longer a Single Discipline
Le SEO n’est plus une discipline unique : proposition de représentation de l’optimisation de la recherche et de la visibilité sur le web (11/01/26) par Duane Forrester autour d’un noyau central SEO puis de deux cercles concentriques, l’ensemble – complexe et holistique – formant le nouveau cadre de travail. Si l’exploration et l’indexation (d’un site, d’une page) demeurent indispensables (sinon le contenu n’est pas accessible), si l’architecture de l’information (une page répond à un objectif précis, selon une une intention et un besoin) au sein de l’arborescence) et l’UX le sont tout autant, cela n’est plus suffisant en 2026, à l’ère des requêtes sur les plateformes IA et des réponses génératives fournies par les LLM.
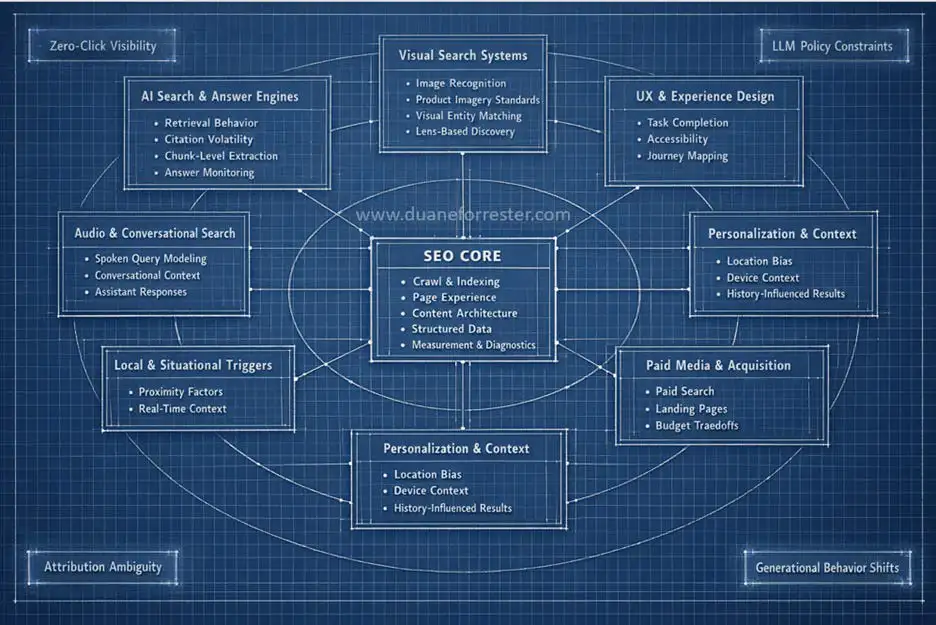
Deux cercles concentriques autour du noyau central SEO Core
Le 2e cercle inclut notamment la capacité à rédiger un contenu cohérent avec des segments (le fameux chunking) dont l’assemblage forme un tout, mais avec la capacité à être extrait(s) par les robots IA. Il prend donc en compte la décomposition des requêtes (Query Fan-Out). Il comprend également la recherche visuelle (photo, vidéo) et audio.
Le 3e cercle est aujourd’hui le plus exploratoire et incertain, touchant par exemple à la protection de la marque quand les LLM font preuve de grande largesse en matière de propriété intellectuelle. Il intègre aussi la stratégie de marque (storytelling, récit) qui englobe la voix, l’identité, la réputation, la présence des dirigeants et la gestion de crise… iIl y a – là – un lien direct avec la confiance inspirée par la marque (et donc sa capacité à acquérir/convertir sur le terrain du marketing). A rapprocher du EEAT pour la traduction en contenus, multimédias et multi/omnicanal.
Le SEO moderne devient une discipline d’intégration
Cette définition donnée par Duane Forrester résume avec justesse l’évolution en cours du SEO (optimisation du référencement naturelle dans sa définition ante-LLM) : « Le SEO moderne fonctionne comme une discipline d’intégration. Il connecte des systèmes qui n’ont jamais été conçus pour fonctionner ensemble. Il assure la traduction entre les machines et les humains, entre l’intention et l’interface, entre le discours de marque et la logique de recherche. Il absorbe la volatilité des plateformes afin que les organisations n’en subissent pas les conséquences simultanément. »
Google Downplays GEO – But Let’s Talk About Garbage AI SERPs
Google minimise l’importance de l’optimisation du contenu pour la recherche générative (GEO), mais parlons plutôt des SERPs IA de piètre qualité : un article Search Engine Journal (13/01/26) qui nous invite à prendre de la hauteur. Que le web et la recherche sur celui-ci sont-ils devenus ? L’article prolonge le débat récent lancé par Dany Dullivan et John Mueller de Google sur l’intérêt (ou non) de tronçonner le contenu éditorial en extraits (chuncking) pour l’optimisation LLM (dite GEO), sachant que nous n’avons pas encore le Mode AI en France. Nous expérimentons cet usage depuis ChatGPT, Perplexity, Claude… quitte à revenir ensuite sur Google pour rechercher une entreprise, une marque.
La recherche informationnelle sur les LLM aboutit à la chute des clics vers les sites
Dès 2012, rappelle l’auteur Roger Monti, Google annonçait « la prochaine génération de recherche, qui exploite l’intelligence collective du web et comprend le monde un peu plus comme les gens ». Nous y sommes avec, en sus, des réponses aux requêtes désormais plus longues (d’une SERP avec des liens voire un extrait enrichi à une réponse générative et synthétique) et que ces réponses adresse la requête principale mais aussi des sous-questions complémentaires selon le principe du Query Fan-Out.
Soulignons que l’évolution de cette pratique de la recherche AI générative aboutit à une chute des clics vers les sites référents, en premier chef pour les requêtes de type informationnelle (l’entrée du tunnel de conversion, le stade de la découverte par un visiteur web encore inconnu).
Cet article est vraiment intéressant car Roger Monti s’écarte du discours général en regrettant l’appauvrissement des SERP générales et la capacité de Google à morceler les résultats en les classant dans de multiples onglets (de Tous à Plus, en passant par Images, Produits, Vidéos…) et rubriques comme Autres Questions où l’on trouve beaucoup d’informations.
Va-t-on vers l’appauvrissement du contenu sur le web ?
Pour le mode AI, que nous découvrirons un jour depuis nos interfaces hexagonales, sa conclusion est assez lapidaire : « Le mode IA de Google favorise les contenus de mauvaise qualité et les sites manquant d’expertise. » Il conviendrait de la confirmer selon une étude quantitative de grande envergure sur des milliers et milliers de requêtes… mais ce que Roger Monti pointe du doigt, à juste titre, « c’est que Google ne référence plus les sites de qualité et que ces sites dépérissent [ndla : ou vont dépérir] faute de trafic […] A quand remonte la dernière fois que vous avez découvert un site vraiment génial que vous aviez envie de partager ? »
Avec le contenu généré par IA qui envahit progressivement le web, le chemin emprunté risque de ne pas être celui de l’originalité (ni biais ni dispersion, moyennisation) mais du flatten content, les itérations algorithmiques « génération IA / recherche IA / génération IA » tendant vers l’uniformité.
Being Right Isn’t Enough for AI Visibility Today
Avoir raison ne suffit plus aujourd’hui pour assurer la visibilité du contenu depuis la recherche IA : un article signé Duane Forrester sur son blog Substack (04/01/26) qui aborde le sujet du vrai et du probable, entre la qualité des réponses et la fiabilité de l’information dispensées à l’utilisateur sur le web, à partir d’une recherche Google ou en réponse à une question posée à une plateforme LLM.
Comme le résume l’auteur : « Les systèmes d’IA ne parcourent pas le web comme les humains. Ils n’évaluent pas les pages une par une, ne pondèrent pas les arguments et ne raisonnent pas pour parvenir à une conclusion. Ils extraient plutôt des informations, les pondèrent, les compressent et génèrent une réponse statistiquement susceptible d’être acceptable compte tenu de ce qu’ils ont déjà vu […] Ce processus introduit un biais avant même la génération d’un seul mot. »
Des réponses IA génératives probables, entre biais de confort et « flatten langage »
Récupération du contenu (et RAG), pondération des extraits (chuncks) et génération de la réponse où « le modèle produit une réponse qui optimise la probabilité, la cohérence et la minimisation du risque […] À aucun moment de ce processus, la neutralité, au sens où on l’entend habituellement, n’existe. Ce qui prévaut, c’est la préférence : préférence pour ce qui est familier, pour ce qui a déjà été validé, pour ce qui correspond aux schémas établis ».
Nous y retrouvons la notion de « flatten language » ou langage aplati déjà pointé par Despina Gavoyannis dans un article Ahrefs en avril 2025 : LLMs Don’t Reward Originality, They Flatten It.
Duane Forrester décrit ainsi ce qu’il nomme « biais de confort » : « C’est la tendance des systèmes de recherche et de réponse de l’IA à privilégier les informations structurellement familières, historiquement validées, sémantiquement alignées sur l’entraînement antérieur et présentant un faible risque de reproduction, qu’elles représentent ou non l’information la plus précise, la plus actuelle ou la plus originale. »
Du biais de classement (SEO) au biais d’existence (GEO)
Du SEO à GEO, quelle conséquence, en intégrant que les biais de recherche traditionnelles existent également : « Lorsqu’un système d’IA produit une réponse synthétique unique, il n’y a pas de classement à consulter. Il n’y a pas de deuxième page de résultats. Il n’y a que l’inclusion ou l’omission. On passe ainsi d’un biais de classement à un biais d’existence.” Avec le risque que la probabilité ne soit pas la vérité (si cette dernière existe encore…). »
Cette chronique est intéressante car elle ouvre une piste sur l’évolution du rôle des professionnels de la visibilité sur le web : de l’optimisation classique à l’interprétation des signaux IA avec la capacité à comprendre et expliquer comment les systèmes de recherche se comportent face à l’incertitude.
Reste une question toujours ouverte : celle de la finalité de ces efforts si, au bout du chemin, le zéro clic devient la nouvelle norme.
Biais IA-IA : les grands modèles de langage favorisent les communications générées par de grands modèles de langage
Si vous souhaitez prolonger la lecture sur les biais, avec une implication à l’échelle des systèmes d’information (SI) des organisations, cet article de recherche (juillet 2025) : AI–AI bias: Large language models favor communications generated by large language models. Il met en évidence que si l’on déploie des assistants basés sur les LLM dans des rôles décisionnels au sein d’une entreprise, ils privilégieront implicitement – en tant que partenaires commerciaux et prestataires de services – d’autres agents d’IA basés sur les LLM et des humains assistés par ces LLM par rapport à de simples humains non augmentés par l’IA.
De la « dénumérisation » à l’explosion des usages : l’impact des data centers sur la consommation électrique en France auscultée
Publication 06/01/26 de l’étude ADEME « Prospective d’évolution des consommations des data centers à court, moyen et long terme de 2024 à 2060 » qui répond à trois objectifs dans un contexte où le fort développement de l’IA, de façon connexe du cloud, du e-commerce, du divertissement en ligne ou bien des services publics dématérialisés entraîne une hausse des usages en croissance permanente des usages. Résumé dans les colonnes du Monde pour le titre ci-dessus et l’article de référence.
Les trois ambitions de l’étude ADEME
- Dresser l’état des lieux de la consommation électrique actuelle des centres de données en France
- Proposer un modèle prospectif détaillé permettant de modéliser des scénarios d’évolution des consommations des centres de données dans le temps
- Modéliser et analyser 5 scénarios prospectifs jusqu’à 2060 : un scénario tendanciel et 4 scénarios envisageant les 4 chemins possibles de transition écologique
Quelques données chiffrées :
- L’ADEME a recensé 352 datacenters actifs en France, en 2024, pour une consommation totale d’environ 10 térawattheures (TWh) d’électricité (sur une consommation annuelle totale du pays de 450 TWh).
- Si les tendances actuelles se poursuivent, l’Ademe estime que cette demande pourrait être multipliée par 3,7 d’ici à 2035 (37 TWh) et par 6,4 à l’horizon 2060
- Les modélisations pour la période post-2035 sont cependant estimées comme « incertaines »
Cinq scénarios prospectifs d’ici 2060 du tendanciel au réparateur
Ces chiffres ne prennent pas en compte les usages importés : « On considère aujourd’hui que la moitié des données traitées pour un usage français le sont hors du territoire, indique Bruno Lafitte, ingénieur à l’ADEME, cité par Le Monde. En 2050, dans un scénario tendanciel, on serait à 78 %. »
Nous retrouvons dans ces travaux la réflexion autour de cinq scénarios prospectifs d’ici 2060 : tendanciel, génération frugale, coopérations territoriales, technologies vertes, pari réparateur. Avec des grands écarts dans les projections selon les hypothèses qui sont le reflet de choix politiques et de société : le total des émissions de CO2 associées baisse de 95% en 2050 par rapport à 2024, ou il est multiplié par 9, rendant plus ou moins difficile le respect des engagements climatiques de la France.
Microsoft CEO, Google Engineer Deflect AI Quality Complaints
Le PDG de Microsoft et un ingénieur de Google esquivent les critiques concernant la qualité de l’IA : un article Search Engine Journal (05/01/2026) qui énonce clairement l’un des problèmes du moment, au cœur du business model de l’économie de l’attention, c’est à dire la relation entre les producteurs et diffuseurs de contenu sur le web vs les BigTech. Ce propos fait écho à des publications récentes, du côté de Microsoft et Google, relativisant ou appelant à dépasser les critiques faites à l’IA générative par les utilisateurs, notamment en matière de faible qualité des contenus numériques déversés à torrent sur les réseaux sociaux. Ce que les correcteurs humains du dictionnaire Merriam-Webster Inc. qualifient de slop et qu’ils ont désigné mot de l’année 2025 : « Le slop content est un contenu numérique de faible qualité, généralement produit en grande quantité par l’intelligence artificielle […] Tout comme la vase, la boue et la fange, le mot «slop» évoque quelque chose d’humide qu’on n’a pas envie de toucher. »
Le Slop AI : ce contenu bouillie qui gangrène le web
Pour prolonger sur le slop AI, partage complémentaire, dans cette chronique n°4, d’un article complet de Anke Wiethoff où l’auteure rappelle bien le but principal de la démarche : « L’IA de piètre qualité sert avant tout un objectif économique de profit, en maximisant la portée et l’engagement sur les réseaux sociaux grâce à une production massive et peu coûteuse de contenu […] Les publications automatisées visent à générer des revenus publicitaires ou des liens d’affiliation en devenant virales le plus possible. »
Un papier Harvard Business Review pour prolonger la réflexion sur les implications de l’IA générative dans les organisations : AI-Generated “Workslop” Is Destroying Productivity
Le clic de qualité : miracle, réalité ou escroquerie ?
Pour en revenir à l’article principal de Search Engine Journal, au-delà des plaidoyers pro-domo de Microsoft et Google, il pointe la rupture de l’accord tacite entre les éditeurs qui autorisent l’indexation de leur contenu en échange de sa distribution et du trafic induit via les moteurs de recherche depuis les SERP. Or les évolutions en cours (Mode AI, recherche ChatGPT) ont une influence directe sur les usages (chute du taux de clics) car le contenu peut servir à répondre à des questions sans nécessiter le même niveau de redirection (ie liens et clics) vers le web ouvert (ie vers les sites des éditeurs) : les réponses génératives, notamment pour les requêtes informationnelles, se suffisent à elles-mêmes.
Le deal est en passe d’être rompu.
Les plateformes LLM et les éditeurs SaaS d’outils d’analyse web nous promeuvent aujourd’hui la mention et la citation IA comme le nouvel indicateur miracle, faisant le lien avec le trafic de marque qu’il faudrait ensuite évaluer dans la Search Console pour apprécier le transfert vers les sites Web. Google nous vend également le clic de qualité !
C’est nébuleux et – comme le rappelle l’auteur Matt G. Sud dans l’article cité – c’est pour mieux éluder le sujet de la baisse du trafic en volume, conjuguée au slop AI qui se déverse en masse sur le Web, qui alimente les réponses des IA génératives adossées aux LLM…
Le clic de qualité est déjà rare. Il pourrait finir par devenir miraculeux.
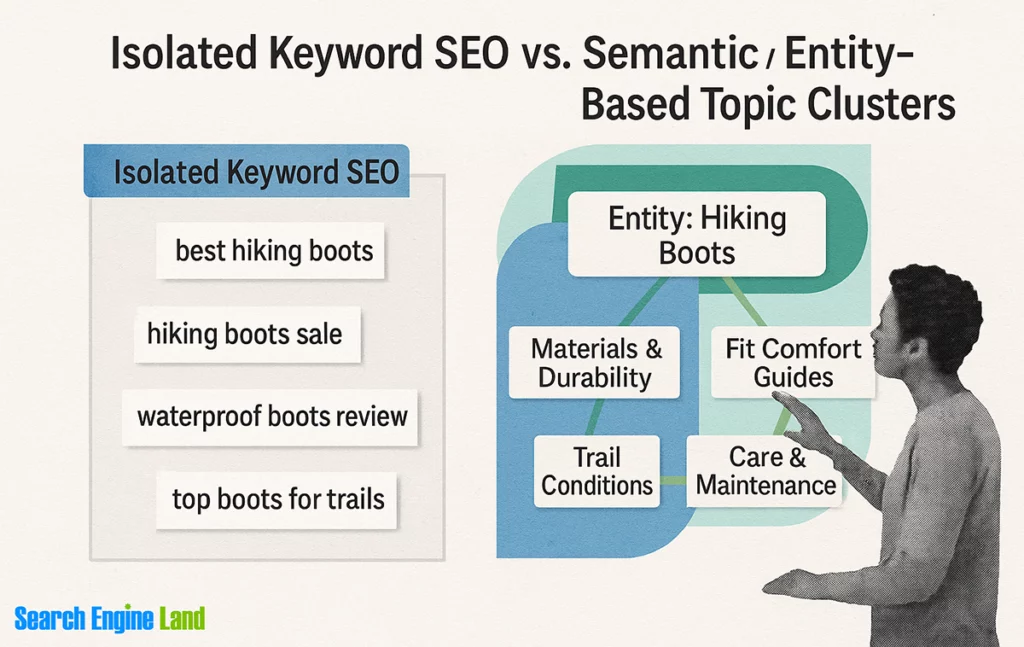
The complete guide to topic clusters and pillar pages for SEO
Le guide complet des clusters thématiques et des pages piliers pour le référencement naturel : un article Search Engine Land (31/12/25) pour comprendre puis déployer une stratégie d’optimisation du référencement naturel (SDEO) en groupes de mots clés. Le but poursuivi est de miser sur une couverture sémantique la plus large possible selon un thème de recherche (transposition opérationnelle du Query Fan-out).
Une façon de s’adapter à l’évolution de la recherche classique (Google) et à la quête de mentions des IA (depuis les questions posées sur les plateformes LLM) sur le web, tout en restant fort (dans le respect des critères EEAT) sur le contenu : l’avantage concurrentiel réside toujours dans la création de contenu qui répond avec précision et clarté aux questions des utilisateurs (selon leur intention).
Pierre Minier
- Chronique IA générative n°1 (08/11/25)
- Chronique IA générative n°2 (25/12/25)
- Chronique IA générative n°3 (03/01/26)



