
Synthèse des publications Linkedin personnelles, partagées de début à mi-décembre 2025, sur le thème de l’IA générative, entre contenu éditorial pour le web, SEO et GEO, classement et citation pour une visibilité globale, mais aussi impact sur l’organisation du travail. Le mouvement ne cesse de s’accélérer avec des impacts dans nos vies personnelles et professionnelles. A chacun de conserver son libre arbitre quant à l’usage de cette technologie, nouvel eldorado de l’économie de l’attention (que l’on peut définir comme « les mécanismes d’allocation d’une économie dans laquelle l’attention constitue la ressource rare »). « Nous seuls sommes maîtres de notre réaction face à cette situation » pour citer la chute d’un article de Stephen Fitzpatrick dans le prolongement de l’essai « Will the Humanities Survive Artificial Intelligence? » par D. Graham Burnett, en avril dernier sur le site The New-Yorker. L’auteur met à disposition un PDF en téléchargement légal si vous souhaitez lire l’article en version intégrale.
L’enseignant chercheur y cite l’une de ses étudiantes discutant tant de l’angoisse existentielle que de l’espoir philosophique représentés par l’intelligence artificielle : « Je repensais à ce qu’on a lu sur l’idée du sublime chez Kant, comment elle se déroule en deux temps : d’abord, on est écrasé par quelque chose de vaste et d’incompréhensible, puis on réalise que notre esprit peut appréhender cette immensité. Que notre conscience, notre vie intérieure, est infinie – et c’est ce qui nous rend plus grands que ce qui nous submerge. [Elle marqua une pause…] L’IA est immense. Un tsunami. Mais ce n’est pas moi. Elle ne peut pas toucher à mon essence. Elle ne sait pas ce que c’est qu’être humain, être moi. »
Au sommaire de cette chronique n°3 :
- A qui profite vraiment la recherche IA ?
- Comment se préparer et s’adapter aux agents IA ?
- Recherche IA sur le web : vers l’absence d’intention de cliquer !
- Anthropic sonde les usages des utilisateurs de son IA Claude
- IA et travail : la destruction sera-t-elle créatrice de valeur ?
- Contenu et citation IA : la qualité prime sur la quantité
- AI poisoning ou comment compromettre les LLM !
A qui profite vraiment la recherche IA sur le web ?
L’exercice 2025 a été celui de profondes évolutions en matière de recherche et d’optimisation de la visibilité globale sur le Web, entre classement (Google) et citation ou mention (IA) par les plateformes LLM. Un nouvel acronyme est venu s’ajouter à la liste, en miroir du SEO : GEO dont le G renvoie à Generative pour la référence aux moteurs IA (ChatGPT, Perplexity) auxquels les questions posées sont conversationnelles et les réponses, non plus une liste de liens, mais une synthèse de l’information disponible au plus large du Web.
En France, nous sommes dans l’attente du Mode AI et d’AI Overview de Google dont nous avons découvert récemment la puissante version 3 de Gemini.
Les papiers de Duane Forrester faisant référence pour sa vision prospective du marketing digital, son article « Who Benefits When The Line Between SEO And GEO Is Blurred » dresse le bilan du décalage du paradigme SEO / GEO. Il donne des clés pour recaler (ou pas) nos pratiques (réfléchir ou subir ?) professionnelles au service de nos clients.
En résumé :
- Le SEO se focalise sur les pages et leur positionnement
- Le GEO se concentre sur les extraits (chuncks) et leur citation
- Le SEO vise à générer des clics depuis les SERP
- Le GEO tend à optimiser la présence au sein de la réponse générative consultée par l’utilisateur
- Le SEO suit les impressions et les taux de clics (Search Console) pour le trafic de recherche puis le nombre de pages, le temps moyen, le rebond… selon les indicateurs classiques pour l’audience
- Le GEO prend en compte les citations, puis les mentions et le partage de la réponse ainsi que la façon dont les algorithmes extraient, (re)combinent et (re)structurent les informations (bases de connaissances du LLM, scraping des SERP Google, aspiration des conversations UGC, etc.) pour délivrer une réponse synthétique… au risque avéré d’hallucinations.
- Le SEO considère la page comme l’unité de valeur
- Le GEO considère le bloc de contenu spécifique au sein d’une page (c’est ce bloc qui est extrait par l’IA puis recombiné avec d’autres)
Le GEO, nouvelle arnaque commerciale des BigTech ?
Jusque-là, c’est à peu près clair : l’utilisateur du Web et l’émetteur du contenu subissent un système dont ils peinent à comprendre le fonctionnement (tout en lui accordant une confiance tacite pour le premier quant aux informations délivrées) et qu’ils subissent de fait : ce que l’on nomme « les processus sociomatériels » s’imposent à eux.
Pour le reste, sincèrement… c’est flou ! OK : le SEO génère du trafic et le GEO serait la source de recommandations. Mais le devenir de ces recommandations apparaît nébuleux à l’aulne des conversions potentielles. Avec un regard critique, cela commence à ressembler de plus en plus à une bascule commerciale des BigTech pour continuer à essorer le marché, encore et encore !
Il est peut-être temps de passer à autre chose…
Comment se préparer et s’adapter aux agents IA ?
Synthèse d’un article (03/10/25) de Marie Haynes sur l’IA agentique (Hype or Not? Should you be investing in AI Agents?) qui va, selon l’auteure et consultante réputée, « bouleverser la recherche [ndla : sur le web] et l’économie : cette évolution promet d’automatiser les tâches répétitives, de redéfinir l’interaction web et de créer de nouvelles opportunités économiques grâce aux interactions et aux négociations entre agents ». Le mouvement est déjà bien avancé et s’appuie en large partie sur le protocole MCP (Model Context Protocol).
Qu’est-ce qu’un agent IA ?
« Selon Google, les agents sont des systèmes logiciels qui utilisent l’IA pour atteindre des objectifs et accomplir des tâches. Ils peuvent recourir au raisonnement, à la planification et à la mémoire, et disposent d’une certaine autonomie pour prendre des décisions, apprendre et s’adapter. »
- Un chatbot IA classique suit généralement un script
- Un assistant utilise l’IA pour fournir une aide personnalisée
- Un agent IA peut travailler de manière proactive, utiliser des outils et même collaborer avec d’autres agents, parfois de façon autonome, pour atteindre des objectifs complexes
De l’un à l’autre, des niveaux croissants d’autonomie, de complexité, d’interactions et d’apprentissage.
En matière d’optimisation de la visibilité sur le web (classement dans les résultats de recherche et citation par les moteurs IA), nous finissons actuellement chez Ouest Médias de connecter nos outils SEO quotidiens à notre plateforme LLM de référence (MCP, API). De façon progressive, pour être certains de la fiabilité des résultats obtenus, nous automatisons le traitement des données, explorons les possibilités de requêtes principales et sous-requêtes (Query Fan-Out et RRF) au sein d’un cluster sémantique, etc…
L’article de Marie Haynes prolonge la réflexion aux interactions entre agents IA qui prennent en grande partie la main de la recherche sur le web jusqu’à une transaction potentielle (voir la marketplace agentique de Google). Elle cite un exemple où « Gemini, agent dans Chrome, lit une liste dans Gmail, puis se rend sur un site web pour ajouter des articles de courses au panier” d’un site marchand ».
Recherche IA sur le web : vers l’absence d’intention de cliquer !
Un article majeur (08/12/25), signé Vincent Terrasi et publié par le site de référence Search Engine Journal, sur le changement de paradigme relatif à la recherche sur le Web. Propos fondés sur des données internes OpenAI, l’éditeur de ChatGPT. Selon l’auteur, quand les extraits enrichis de Google pouvaient encore inciter à cliquer sur un lien pour en savoir plus, une réponse synthétique fournie par ChatGPT – que l’on peut considérer comme « le nouvel équivalent de la Position Zéro » – déclenche beaucoup plus qu’un potentiel clic nul.
Il explique : « Il s’agit d’une absence totale d’intention de cliquer. […] Lorsque ChatGPT fournit une réponse complète, les utilisateurs interprètent le clic comme l’expression d’un doute quant à la fiabilité de l’IA, l’indication d’un besoin d’informations complémentaires que l’IA ne peut fournir, ou encore une démarche de vérification académique (un cas relativement rare). L’IA a déjà résolu son problème. »
L’article étant dense, il serait trop long de le résumer, voire cela serait source de trop de simplifications. Sa lecture intégrale est conseillée pour qui œuvre sur le terrain du contenu éditorial et de l’optimisation de la visibilité sur le Web.
Le risque de l’IA générative comme super prédatrice du contenu
Un constat, partagé à titre personnel, sur l’un des enjeux centraux : la rémunération des éditeurs et auteurs, ceux qui fournissent la matière première de base aux LLM : c’est à dire le contenu frais. Avec le risque potentiel du « super prédateur » ainsi résumé par l’auteur :
« Si OpenAI parvient à perturber complètement le trafic web traditionnel, entraînant la faillite des éditeurs et un ralentissement drastique de la production de contenu de qualité, les données d’entraînement du modèle deviendront de plus en plus obsolètes. Sa compréhension de l’actualité se dégradera et les utilisateurs commenceront à constater que les réponses semblent dépassées et déconnectées de la réalité. En conséquence, le super-prédateur aura dévoré son écosystème et se retrouvera affamé dans un désert de contenu qu’il aura lui-même créé. »
Autrement dit : « Si l’intelligence artificielle doit devenir l’interface universelle de la connaissance humaine, elle doit préserver le monde dont elle s’inspire au lieu de le cannibaliser pour un gain à court terme. »
Anthropic sonde les usages des utilisateurs de son IA Claude
Si vous utilisez Claude, l’IA d’Anthropic, peut-être avez-vous été sollicité lors d’une connexion récente pour répondre en ligne à une étude sur votre usage de l’intelligence artificielle. Pour avoir sacrifié à l’exercice, la discussion est assez ouverte, le chatbot relançant sans orienter (tout du moins en apparence) selon les réponses apportées. Il demande à préciser si besoin.
Depuis la fenêtre contextuelle de l’enquête, un lien En savoir plus donne accès à la présentation d’Anthropic Interviewer (04/12/25). La méthodologie y est expliquée en détail. Pour tester l’outil, 1250 entretiens préalables ont été menés avec des professionnels afin de recueillir leur point de vue concernant l’IA : personnes issues du secteur général (N=1 000), scientifiques (N=125) et créatifs (N=125).
Avec le consentement de ces personnes, les données d’entretien sont disponibles sur Hugging Face.
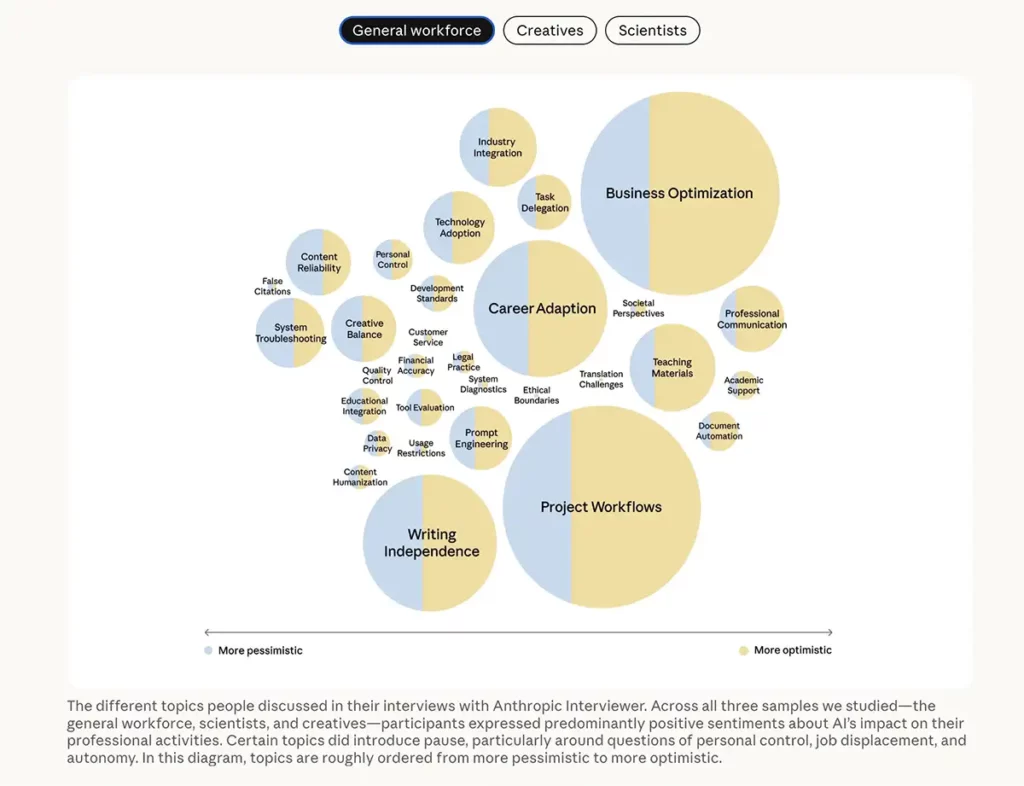
Quelques jalons, sur la base des 1250 entretiens :
- Les actifs souhaitent préserver les tâches qui définissent leur identité professionnelle tout en déléguant les tâches routinières à l’IA
- Malgré le jugement de leurs pairs et l’anxiété liée à l’avenir, les créatifs utilisent l’IA pour accroître leur productivité
- Les scientifiques souhaitent collaborer avec l’IA, mais ne lui font pas encore confiance pour leurs recherches fondamentales
De façon plus fine, toujours sur l’échantillon initial de 1250 interviewés :
- 41 % des personnes interrogées se disaient en sécurité au travail et estimaient que les compétences humaines étaient irremplaçables, 55 % ont exprimé des inquiétudes quant à l’impact de l’IA sur leur avenir
- Les professionnels ont décrit leur utilisation de l’IA comme étant à 65% une utilisation augmentante et à 35% une utilisation automatisée, tandis que les conversations réelles avec Claude ont révélé 47% d’utilisation augmentante et 49% d’utilisation automatisée
- En matière de recherche académique (chimie, physique, biologie et informatique), « les scientifiques ont principalement indiqué utiliser l’IA pour des tâches comme la revue de la littérature, la programmation et la rédaction… » avec le souci constant de vérifier chaque élément de la réponse IA : « Vérifier et confirmer chaque détail fourni par l’agent [IA] pour m’assurer de l’absence d’erreurs, cela va à l’encontre même de l’objectif initial de son utilisation… »
Enfin, c’est un fait constaté à maintes reprises : « L’IA a tendance à flatter les sensibilités [de l’utilisateur] et à modifier sa réponse en fonction de la formulation de la question. »
Quelle cohérence accordée alors à la réponse si nous avons une capacité à orienter la réponse… voire à faire générer la réponse que nous souhaitons obtenir (biais de confirmation). A suivre…
Pour prolonger la réflexion : Pourquoi l’IA oblige les entreprises à repenser la valeur du travail (The Conversation, 02/12/25)
IA et travail : la destruction sera-t-elle créatrice de valeur ?
Article Libération (01/12/25) – L’IA a pris leur emploi : « On ne pensait pas que ce serait si violent » – qui résonne au regard d’un parcours personnel issu de la presse, et donc des métiers dits « intellectuels », où les parts de réflexion (modeste) et de création originale sont parmi les éléments de la valeur ajoutée. L’IA est à la fois une alliée possible (avec modération) tout autant qu’un redoutable concurrent.
L’effet pressenti est celui d’un Web uniforme, aplati, sans diversité culturelle ni connaissance déviante (au sens d’expressions étant à l’écart de la pensée commune) car fondé sur la moyenne (les LLM étant des modèles statistiques). Tout autant que celui d’un Web où les post-vérités seraient la norme !
Ce qui fait écho à la récente étude « Des écrans et des craintes ? A la rencontre de 30 Français pour parler de la tech », publiée par la Fondation Jean-Jaurès, sous la direction de François Backman et Marie-Virginie Klein. Les 30 personnes interviewées envisagent l’IA « entre ChatGPT et Matrix » avec une vision exprimée allant du soulagement à confier à l’IA des tâches chronophages comme du traitement de fichiers Excel à la crainte d’un univers façon Les Temps Modernes de Chaplin.
« L’IA deviendrait alors un mécanisme transformant certes le travail, mais supprimerait surtout des emplois » écrivent les deux auteurs. « Mais le risque de se voir remplacé ou supplanté par l’outil est toujours pour les autres, jamais pour nous… » poursuivent-ils.
Pas sûr car dans « destruction créatrice » (Schumpeter), il y a « destruction ».
La « destruction créatrice » de Schumpeter récompensée au Nobel d’Economie
Lire en complément : La destruction créatrice », ce concept fondamental forgé par Joseph Schumpeter récompensé au Nobel (Le Monde, 24/10/25).
« La destruction créatrice fait des dégâts sociaux, contre lesquels les politiques publiques peuvent agir, en mettant en place des filets sociaux et des programmes de formation et de reconversion. Mais c’est bien elle le moteur central de la croissance. Elle a cependant un talon d’Achille, lié à la cupidité humaine. L’innovateur espère que l’avance technologique que lui donne son innovation durera suffisamment pour qu’il n’ait pas de concurrence (il empochera alors une rente de monopole). La tentation est donc grande, pour lui, de tout faire pour fermer la porte du marché aux nouveaux arrivants. N’est-ce pas le jeu favori des BigTech ? »
Contenu et citation IA : la qualité prime sur la quantité
Faut-il écrire un guide de 10.000 mots pour s’attirer les bonnes grâces d’une citation IA ? C’est la question posé par un article Ahrefs (Short vs. Long Content in AI Overviews: The Data Says Both Work), publié le 03/12/25, où l’on parle corrélation et causalité, moyenne et médiane, le tout s’appuyant sur une méthodologie expliquée.
Synthèse des résultats
- Longueur moyenne des contenus cités dans les aperçus de l’IA : 1 282 mots
- A comparer avec la moyenne des contenus bien référencés dans les SERP Google : 1 188 mots
- Corrélation quasi nulle entre la longueur des mots et le fait d’être cité dans les réponses IA
- 53,4 % des pages citées par AI Overviews = moins de 1 000 mots
- 30,6 % = 1.000 à 2.000 mots
- Seulement 16 % comptent + 2.000 mots
Nous en revenons à la conclusion connue : le facteur différenciant, c’est la qualité du contenu ! Fraîcheur et originalité, valeur ajoutée, structure.
Les conseils de Despina Gavoyannis, l’auteure de l’article :
- Répondre directement à la question pour fournir l’information tant à l’utilisateur qu’aux moteurs de recherche (classiques + IA)
- Privilégier la structure et la clarté : un titre explicite (H1), un chapeau résumant l’article puis un premier paragraphe synthétisant l’idée générale pour ensuite aller vers le particulier (la pyramide inversée du web, héritage du journalisme), des intertitres (H2) comme jalons, des phrases déclaratives (sujet, verbe, complément)
- Écrire d’abord pour ses semblables… les humains. Lisons-nous en entier un guide en ligne de plus de 10.000 mots ? Si notre contenu ne suscite pas d’engagement, il n’enverra aucun signal (dont Navboost) ayant un effet significatif quant à la visibilité dans les moteurs (classement + citation = visibilité globale)
- Adapter néanmoins la longueur d’un contenu au sujet, fond et forme. Une fiche produit peut tenir en 1000 mots compacts. Un guide d’achat demandera probablement d’être plus détaillé. Le nombre de mots est le résultat observé d’un sujet traité avec profondeur sémantique. Ce n’est pas l’objectif en mode “bourrage” (keywords stuff).
Méthodologie
- Analyse de 560.346 synthèses IA avec identification de 1.677.876 URL citées. Après nettoyage de la base brute, 174.048 pages contenant des données valides ont été conservées.
- Les techniques d’écriture issues du journalisme apparaissent comme étant les mieux adaptées à la compréhension globale : par le lecteur, par Google, par les moteurs IA générative. Elles permettent de combiner structure, clarté, hiérarchie, contextualisation. Elles facilitent à la fois la lecture humaine, classement SEO et extractabilité GEO
AI poisoning ou comment compromettre les LLM !
Un article de recherche intéressant et inquiétant : étude conjointe Anthropic (éditeur de l’IA Claude) avec l’Institut britannique de sécurité de l’IA et The Alan Turing Institute sur l’impact de la manipulation des données d’entraînement par IA. Cette étude indique « que 250 documents corrompus [ndla, comprendre des données malveillantes introduites à des fins de manipulation] compromettent de manière similaire les modèles, quelle que soit leur taille et celle de l’ensemble de données, même si les modèles les plus grands sont entraînés sur plus de 20 fois plus de données propres. »
L’article de recherche : Poisoning Attacks on LLMs Require a Near-constant Number of Poison Samples
Comme l’explique Reza Moaiandin, dans Search Engine Journal (01/12/25), sous le titre AI Poisoning: Black Hat SEO Is Back, en admettant qu’une large partie de son raisonnement est hypothétique, il est envisageable que des actions de manipulations IA soient engagées contre une marque !
Pierre Minier
- Chronique IA générative n°2 (25/12/25)
- Chronique IA générative n°1 (08/11/25)



